11 Statistics in R
This section demonstrates, and gives a brief description of, some functions to perform statistical analyses.
11.1 Comparing two means of a population or sample(s) using a t-test
Consider two hypotheses: the null hypothesis, \(H_0\), and the alternative hypothesis, \(H_1\). We are interested in testing if the mean of a sample x is equal to the mean of a population (or sample) y. The null hypothesis and alternative hypothesis are:
\(H_0: \mu_x = \mu_y\)
\(H_1: \mu_x \neq \mu_y\)
11.2 Types of tests
Depending on what you want to test, there are different names for different types of tests.
Two-sided tests (not equal to):
\(H_0: \mu_x = \mu_y\)
\(H_1: \mu_x \neq \mu_y\)
One-sided tests:
Lower-tailed test (less):
\(H_0: \mu_x \ge \mu_y\)
\(H_1: \mu_x < \mu_y\)
Upper-tailed tests (greater):
\(H_0: \mu_x \leq \mu_y\)
\(H_1: \mu_x > \mu_y\)
11.3 p-values and statistical significance
The p-value is a measure of the probability that an observed difference could have occurred just by random chance. The smaller the p-value is, the less likely the difference is due to chance.
The significance value, \(\alpha\) (alpha), will determine the threshold p-value for rejecting our null hypothesis when it is actually true. A significance level of \(\alpha=0.05\) is often used.
11.4 t.test
We use a t-test to compare two means. For example, suppose x is the change in weight of 10 domestic cats weighted one week apart. We will test if we can reject the null hypothesis that the mean of the sample, mean(x), is equal to 0 (the hypothesized mean value in the population of domestic cats). Our two hypothesis are:
\(H_0: \mu = 0\)
\(H_1: \mu \neq 0\)
Below, we generate some example data, x, to illustrate how to perform a t.test (when performing your analysis, this step is replaced with the step of loading or entering your data, i.e., see Chapter 8).
## [1] -0.5474349 -0.8788733 -0.6140130 0.4456452 1.1520274 -0.4896528
## [7] 0.6920856 -0.7118569 2.2082143 -1.6894273Before running the analysis, we decide to set \(\alpha = 0.05\). Perform the test:
##
## One Sample t-test
##
## data: x
## t = -0.1191, df = 9, p-value = 0.9078
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -0.8663161 0.7796589
## sample estimates:
## mean of x
## -0.04332857Running this code, gives p-values greater than \(\alpha = 0.05\). Therefore, we fail to reject the null hypothesis that the weight change in the population of domestic cats is 0. As such, our data suggest that the cats have not changed weight.
The t.test function can be expanded by using additional arguments or changing arguments as required. For example, we can performed a one-sided test.
t.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE,
conf.level = 0.95, ...)
x(required) : data to be analized
y(optional) : data to be compared to. The default value is NULL
alternative (optional) : this refers to what you want to test: ("two.sided","less","greater").
By default this value will be "two.sided"
mu (optional) : indicates the true value of the mean. Default value = 0
paired (optional) :indicates whether you want a paired t-test. Default value = FALSE
var.equal (optional) : indicates if the variances are equal. Default value = FALSE
conf.level (optional) : confidence level of interval. Default value = 0.95
EXERCISE 11.1
Suppose the 10 measures of change in cat weight were instead:
## [1] 1.4714392 0.5318269 0.3799905 2.0060699 0.2578247 -0.1141434
## [7] 2.3378861 2.1618994 0.9296003 2.1565953Using the code above to generate the example data,
x2, perform a t-test with the null hypothesis that the change in weight of the cat population was 0.Perform a t-test with the null hypothesis that the cats in the sample,
x2have lost weight.Use the command
t.test(x,x2)to test if the mean of the samplexis equal to the mean of the samplex2.Suppose two samples are exactly the same. Would you expect to reject the null hypothesis? Try
t.test(x,x).
11.5 Correlation
Correlation, \(r\), is a statistical measure that describes if two variables are linearly related (meaning they change together at a constant rate). The correlation coefficient, \(r^2\), measures the proportion of the variance of one variable that can be explained by the straight-line dependence on the other variable.
- For positively-associated variables, an increase in one variable accompanies an increase in the other variable, and \(r > 0\):
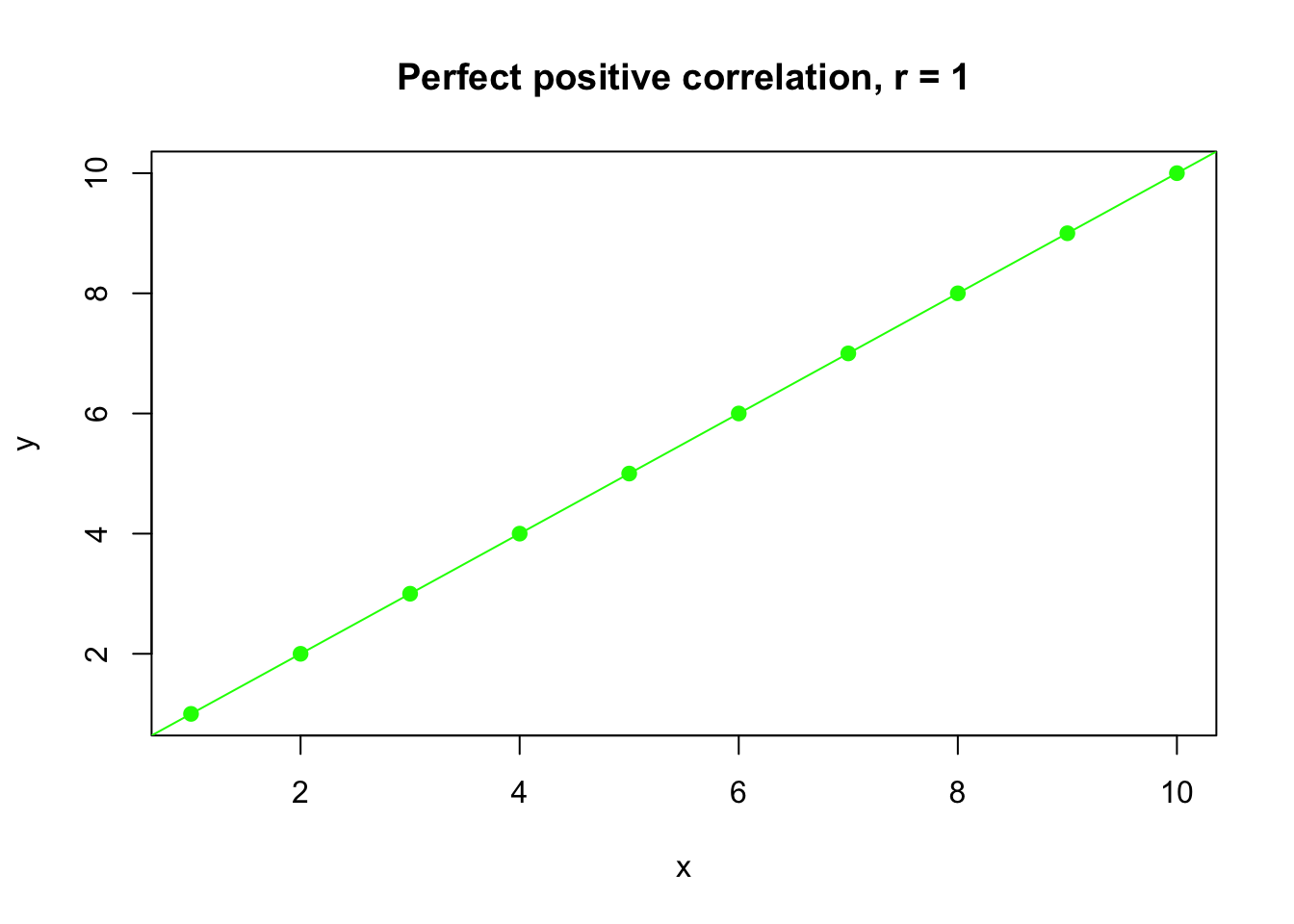
## [1] 1For the output above, the value 1 means \(r=1\), indicating a perfect positive correlation between two variables.
- For negatively-associated variables, an increase in one variable accompanies a decrease in the other variable, and \(r < 0\):
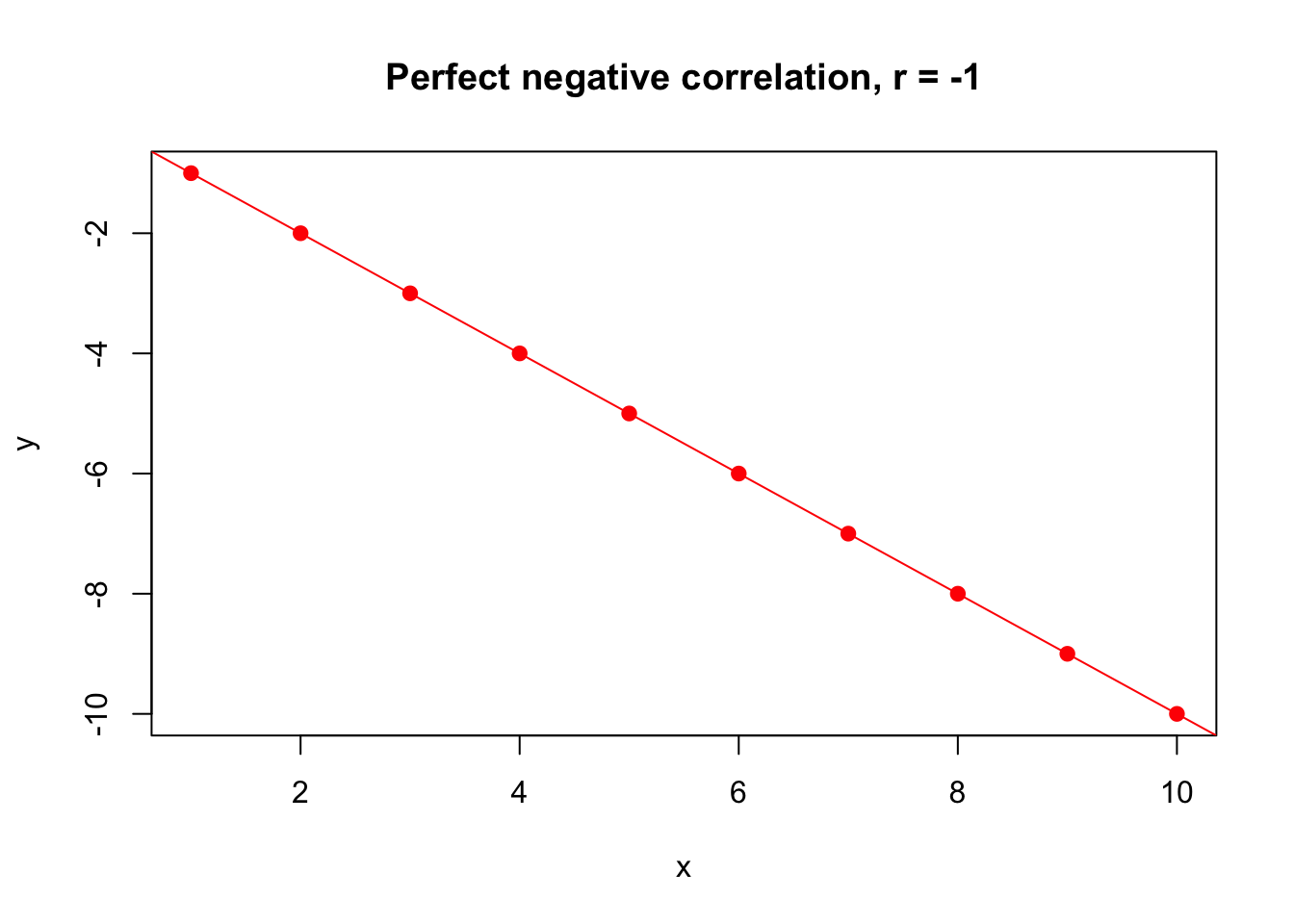
## [1] -1For the output above, the value -1 means \(r=-1\), indicating a perfect negative correlation between two variables.
- When two variables are not correlated, \(r\) is near 0:
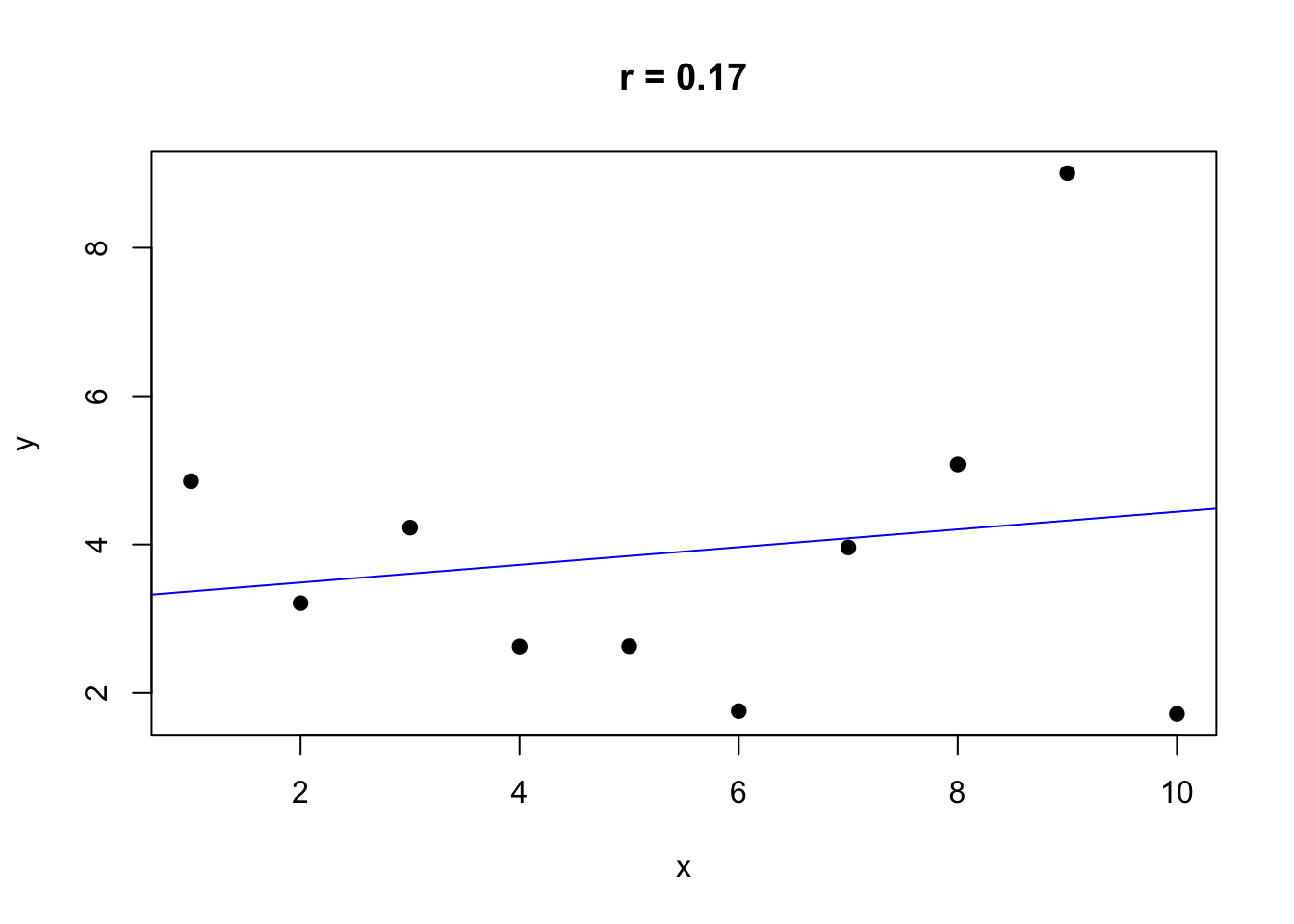
## [1] 0.168460711.5.1 cor(x,y)
The correlation coefficient, \(r\), is calculated with the corr(x,y) function. The function has two mandatory arguments, x and y, which are lists of values of equal length:
## [1] 0.9939441EXERCISE 11.2
Can you write the code to graph
xandyfrom the code above to show the positive correlation? (see Chapter 10 if you need help)Can you change
yin the above code to yield negative correlation?
11.6 Simple linear regression
Similar to correlation, simple linear regression analysis can determine if two numeric variables are linearly related. Linear regression estimates parameters in a linear equation that can be used to predict values of one variable based on the other. The simple linear regression equation is often represented in the form y = mx + b. Here, m represents the slope of the line and b represents the y-intercept.
A line of best fit represents a trendline that approximates the relationship between points of a scatter plot. Most often, we will use a linear equation to estimate this relationship.
We can calculate this equation by hand but R will do this for us using the function abline(), specifying lm() for linear model. The syntax we use for the equation is lm(y-variable ~ x-variable).
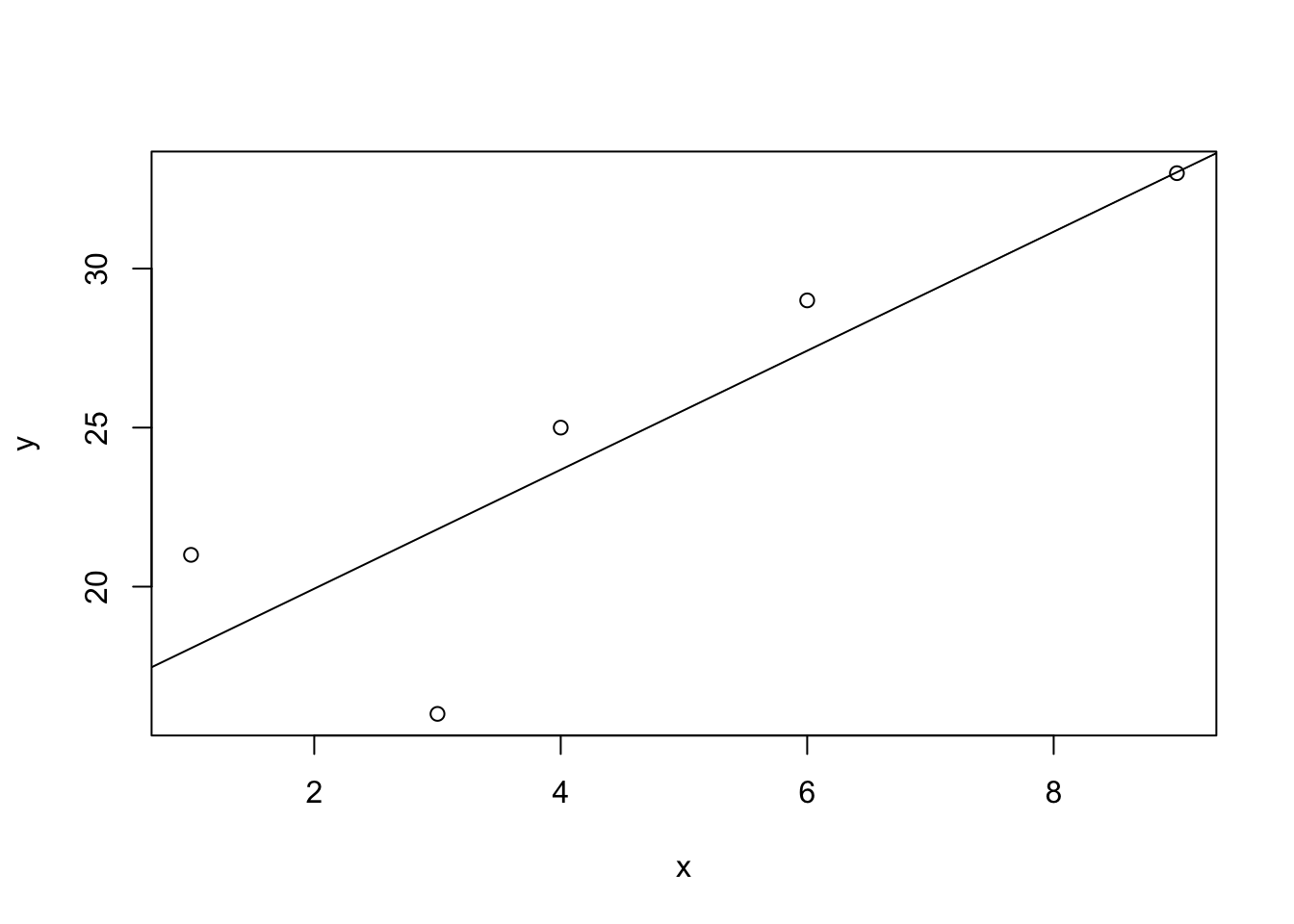
Note that we use the abline() function after plot(). This will add the line of best fit to the existing plot, but it will not plot a line on its own.
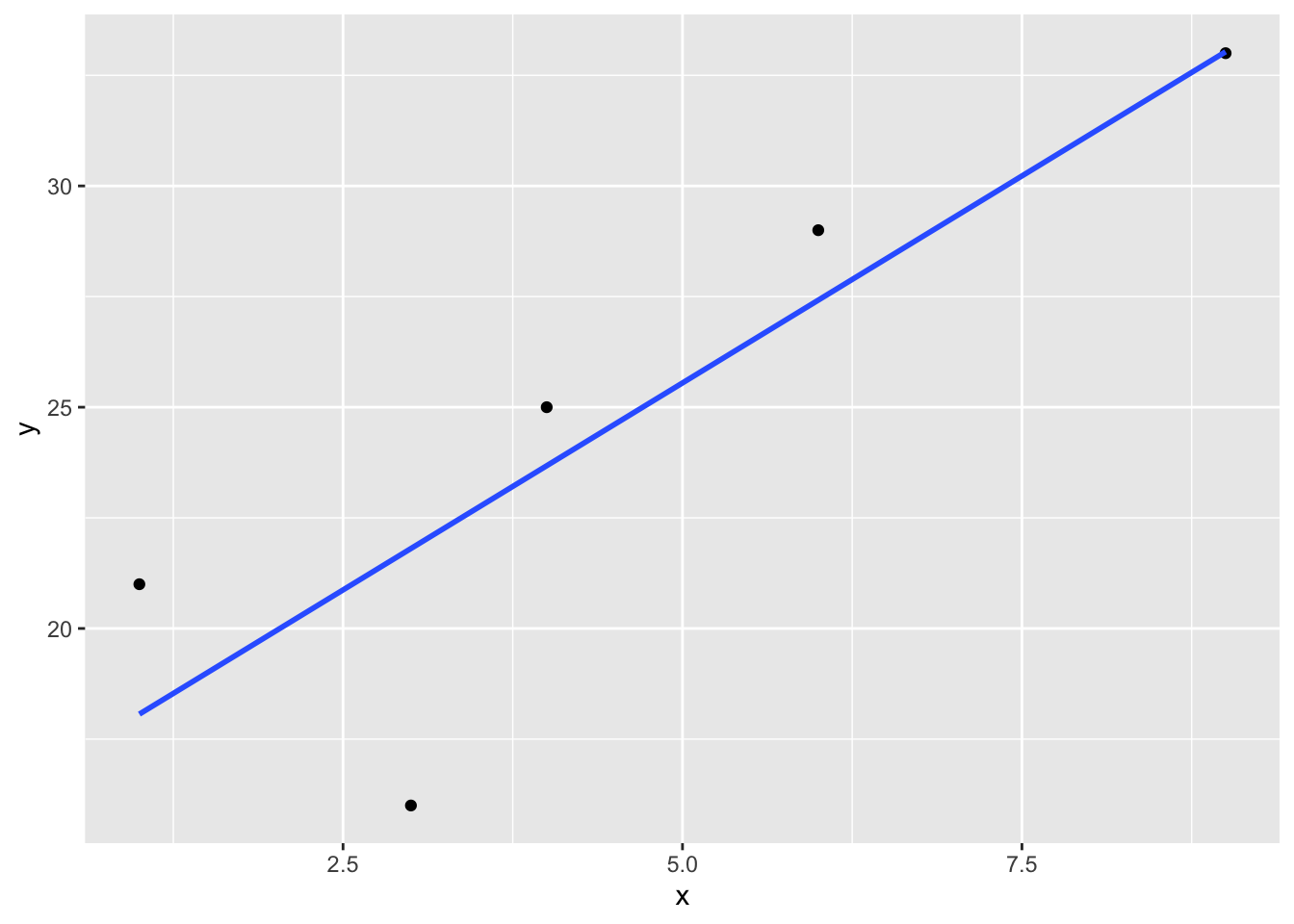
11.6.1 Adding lines of best fit with ggplot
When creating figures with 15, we build layers of our graphic by adding additional geoms. This is also the case if we want to add a line of best fit. We build our scatterplot by specifying geom_point, then use geom_smooth for the regression line, specifying method = "lm" for a linear model.
x <- c(1, 3, 4, 6, 9)
y <- c(21, 16, 25, 29, 33)
df <- data.frame(x, y)
ggplot(data = df, aes(x = x, y = y)) +
geom_point() +
geom_smooth(method= "lm", formula = y ~ x, se = FALSE)